
Using GeoNet’s AWS Open Data
Welcome, haere mai to another GeoNet Data Blog. Today, we look at GeoNet’s use of the AWS (Amazon Web Services) Open Data Sponsorship Program, and how our data users can make use of the program to access our data, particularly large volumes of our data. We will explain what AWS Open Data is and give some simple examples of how you can use it to access our data.
In 2022 GeoNet was the first organization in Aotearoa New Zealand to join the AWS (Amazon Web Services) Open Data Sponsorship Program, where AWS covers the cost of storage for publicly available high-value cloud-optimized datasets.
By using the AWS Open Data Sponsorship Program, GeoNet is able to eliminate unexpected costs associated with users downloading large datasets, while providing end-users with free and open access to its entire archive. Whether you want to download large volumes of data into your local working environment or work closer to their source in the cloud, the ease and speed of GeoNet big data access has undergone a step-change. In this blog we’ll go over what GeoNet data being in the Open Data Sponsorship Program means to our users and how you can make the most of this. Specifically, we’ll cover how to discover and access data in the GeoNet Open Data bucket.
Disks, files and folders in AWS
We are all familiar with the concept of disks, files and folders on our desktop computer. In the AWS world, the concepts of disks, files and folders change a little. It’s important you understand this so you can work with AWS cloud storage more easily and follow the “how to” we are going to provide a little later. In simple terms, this is what's what.
| Computer name | AWS cloud name |
|---|---|
| storage location/disk | bucket |
| file | object |
| folder | object prefix |
This will become a little clearer with an example:
geonet-open-data/camera/volcano/images/2023/DISC/DISC.01/2023.180/2023.180.2340.00.DISC.01.jpg
- geonet-open-data/ is the bucket name (our computer disk)
- camera/volcano/images/2023/DISC/DISC.01/2023.180/ is the object prefix (our computer folder)
- 2023.180.2340.00.DISC.01.jpg is the object (our computer file)
As objects in a bucket are ordered by their object prefix, the object prefix resembles (and acts like) a computer folder.
In this example, we refer to the date as “2023.180”. This means the 180th day of 2023, June 29. If that’s not familiar to you, we touched on that in an earlier blog on webcam images.
In this case, the bucket/object-prefix/object refers to a webcam image, specifically this one. An unremarkable image that shows Mt Ruapehu obscured by cloud!

Mt Ruapehu webcam image
There’s one more concept we need to explain before our “how to”. This is how AWS specifies the type of computer system. AWS offers resources (computers) on which you can process data, run web sites, etc. There are also resources specifically designed to host databases. For GeoNet’s Open Data we use a storage resource, as we are storing and making available data. AWS offers several storage resources, but for GeoNet Open Data we use the Simple Storage Service, commonly abbreviated to “S3”. To fully specify the location of the Ruapehu image file, we need to precede the file location with “s3://” to give the complete file specification.
S3:// geonet-open-data/camera/volcano/images/2023/DISC/DISC.01/2023.180/2023.180.2340.00.DISC.01.jpg
You can find a list of datasets available via AWS on the dedicated data access page on the GeoNet website, and more details of how objects and prefixes are organized for each datasets in the GeoNet data tutorials.
Setup to use GeoNet Open Data
To use GeoNet open data you don’t need an AWS account! You can work with the GeoNet Open Data bucket in different ways. In this blog post we will focus on how you can interact with it using the AWS Command Line Interface (CLI) or using the python boto3 library, which you can both install and run on all common computer operating systems. We know this focuses on our “geekier” data users, but we think they are the ones more likely to be wanting large data volumes and to potentially process data in the cloud.
We know that some of our data users are not so comfortable using the “command line” and prefer the click and scroll of a graphical user interface (GUI). There are a few GUI software packages compatible with AWS Open Data and we are intending to investigate one or two of these. When we’ve done that, we’ll try to report back on our experiences.
We tend not to provide specific instructions on the GeoNet Data Access pages on our website, as these tools are developed by AWS and might change in time. AWS does a great job themselves in maintaining their official documentation. You can learn about it here, and how to use it here.
In this blog, we will show a couple of simple examples to get you started. We also have a short tutorial with additional examples if you want to dig deeper.
How to, AWS Command Line Interface
You can find out how to install AWS CLI here, Windows, Mac and Linux are all supported!
As you would do with a computer folder, you might want to list the content and check what data are available. Here are two examples to list all camera images available for the same day.
To list what camera images are available, you will need to type a command like:
aws s3 ls --no-sign-request s3://geonet-open-data/camera/volcano/images/2023/DISC/DISC.01/2023.180/
The output of this command looks like this (the output is abbreviated):
2023-06-29 15:19:46 0
2023-06-29 15:19:46 245696 2023.180.0000.00.DISC.01.jpg
2023-06-29 15:19:47 254216 2023.180.0010.00.DISC.01.jpg
2023-06-29 15:19:46 246957 2023.180.0020.00.DISC.01.jpg
2023-06-29 15:19:46 263347 2023.180.0030.00.DISC.01.jpg
The first column is when each image file was transferred to the Open Data bucket, the second is the file size in bytes (so about 250 KB each), and the third is the image file name.
If you would like to do the same using python code, you will need to use the “boto3” library. That library is a python wrapper for the AWS CLI. To list objects, you will first set up boto3 to query an S3 bucket, and then request it to list objects for the GeoNet Open Data bucket with the prefix you are interested in.
import boto3
from botocore import UNSIGNED
from botocore.config import Config
s3 = boto3.client('s3', config=Config(signature_version=UNSIGNED))
mydict = s3.list_objects(Bucket='geonet-open-data', Prefix=’camera/volcano/images/2023/DISC/DISC.01/2023.180/')
The output returns a python dictionary (mydict). It contains a lot of information about the files, and you’ll have to extract what you need from that. Here’s an abbreviated section of the output:
{'ResponseMetadata': {'RequestId': 'YVDFVJHKCJBY5SZ2',
'HostId': 'VcADTRmPhL9DOabMd3MRN9WH4sG0Qrusarpifd7kdw5K7W/uaI7XLB+m99aSsiL+IvEwiDrAk6Q=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'VcADTRmPhL9DOabMd3MRN9WH4sG0Qrusarpifd7kdw5K7W/uaI7XLB+m99aSsiL+IvEwiDrAk6Q=',
'x-amz-request-id': 'YVDFVJHKCJBY5SZ2',
'date': 'Sun, 30 Jul 2023 23:01:47 GMT',
'x-amz-bucket-region': 'ap-southeast-2',
'content-type': 'application/xml',
'transfer-encoding': 'chunked',
'server': 'AmazonS3'},
'RetryAttempts': 0},
'IsTruncated': False,
'Marker': '',
'Contents': [{'Key': 'camera/volcano/images/2023/DISC/DISC.01/2023.180/',
'LastModified': datetime.datetime(2023, 6, 29, 3, 19, 46, tzinfo=tzutc()),
'ETag': '"d41d8cd98f00b204e9800998ecf8427e"',
'Size': 0,
'StorageClass': 'INTELLIGENT_TIERING',
'Owner': {'DisplayName': 'geonet.ops.aws.open-data',
'ID': 'dc2eddecc2a94655a7902659a7863024ef6910b7e1ff01950f8df033cd557623'}},
{'Key': 'camera/volcano/images/2023/DISC/DISC.01/2023.180/2023.180.0000.00.DISC.01.jpg',
'LastModified': datetime.datetime(2023, 6, 29, 3, 19, 46, tzinfo=tzutc()),
'ETag': '"97b054c8396c42e9fc1a249fb5e9d6b6"',
'Size': 245696,
'StorageClass': 'INTELLIGENT_TIERING',
'Owner': {'DisplayName': 'geonet.ops.aws.open-data',
'ID': 'dc2eddecc2a94655a7902659a7863024ef6910b7e1ff01950f8df033cd557623'}},
{'Key': 'camera/volcano/images/2023/DISC/DISC.01/2023.180/2023.180.0010.00.DISC.01.jpg',
'LastModified': datetime.datetime(2023, 6, 29, 3, 19, 47, tzinfo=tzutc()),
'ETag': '"9e361b1b45e8ce34ce3c93549d9fc117"',
'Size': 254216,
'StorageClass': 'INTELLIGENT_TIERING',
'Owner': {'DisplayName': 'geonet.ops.aws.open-data',
'ID': 'dc2eddecc2a94655a7902659a7863024ef6910b7e1ff01950f8df033cd557623'}}
You can find some more examples and explanation in the snapshots of code used for this blog in the GeoNet data tutorials, where you will also find a couple of examples to download objects to your local folder.
A complete reference on how to use these tools is available from AWS, so always refer to the official documentation for up-to-date instructions.
Why is this convenient for data users?
If you usually download just a few files, then our "normal” access mechanisms are just fine. But if you are interested in using large volumes of data or want to explore how to process data directly in the cloud, then our normal access mechanisms are either too slow or not equipped to provide you with the volume of data you need at a cost that is sustainable for us.
We have done some tests to see the difference between using our normal access applications or the AWS GeoNet Open Data bucket.
GNSS Data
If you want to download GNSS RINEX data, the normal channel is our data repository available via https://data.geonet.org.nz . If you only need to download one file, the HTTPS mechanism is much faster (it takes way less than one second). But as soon as you want data from many stations (or many files) then AWS Open Data becomes much faster: to download 3GB of data (about 10 days of all our GNSS stations), will take about a minute using AWS CLI and more than 3 minutes using HTTPS.
The figure below shows the time (in seconds) to download example GNSS data.
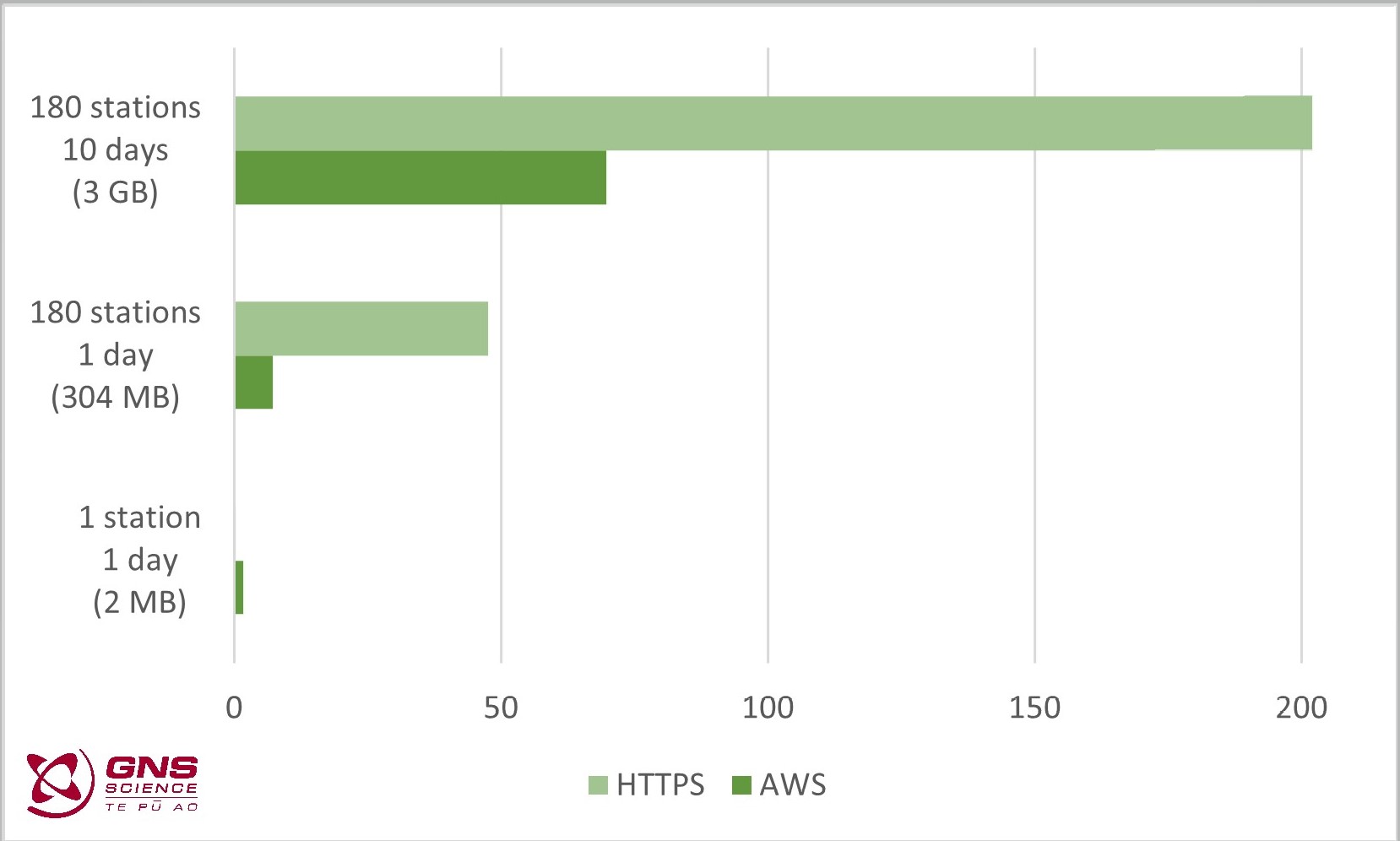
Time (in seconds) to download example GNSS data
If you are interested in downloading files, AWS CLI also offers a “synchronise”, commonly abbreviated to “sync”, option. This means you can download everything from a AWS “folder” and then if you later want to update what you have “sync” will only grab what has changed. Way quicker than downloading everything again!
Seismic Data
If you want to download seismic waveform data, the normal channel is our FDSN archive webservice https://www.geonet.org.nz/data/access/FDSN. The FDSN service works well for small amounts of data, e.g., waveforms from a number of stations that recorded a specific earthquake event.
The FDSN service isn’t optimal for large data requests. For example, downloading all data from 7 stations for a 10-day time window will be pretty slow for you and expensive for us. Our experienced data users have generally developed workarounds to manage this, but they are still comparatively inefficient. Using AWS Open Data, it takes about 4 minutes to download 12 GB of miniSEED data (all data collected on a typical day), and this can be done with a single command.
It is important to note that the miniSEED waveform data available in AWS Open Data are the same as is available using our FDSN archive webservice. Data available using our FDSN near real-time service is not available in AWS Open Data. That means you can only get data older than seven days through AWS Open Data.
The figure below shows the time (in seconds) to download example miniSEED data.
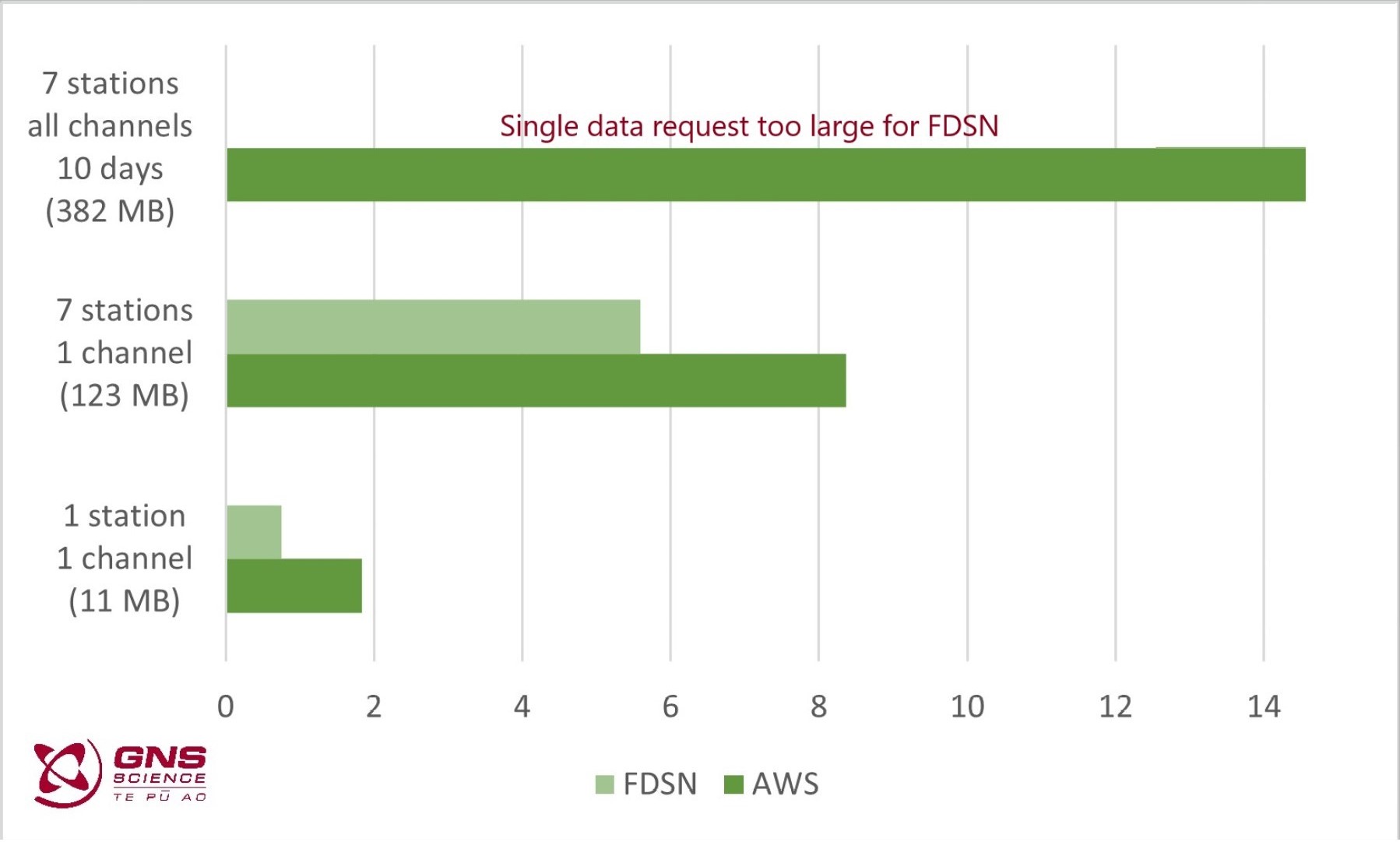
Time (in seconds) to download example miniSEED data.
We need your help!
For “digital waveform” data we only make available in AWS Open Data, data which have metadata we believe are accurate. This means that not all miniSEED waveform data available via FDSN are available from AWS Open Data. This is a situation we’d like to fix, and we could use your help. If you know of data that you can retrieve via FDSN archive but cannot find in AWS Open Data, please get in touch with us and we’ll look into it.
If you have a specific data problem and want to get in contact with us, please open an issue on https://github.com/geonet/help,where you can also check if others had similar problems before you. You can also send us an email.
That’s it for now
That ends our quick look at AWS Open Data. Cloud-based data is something GeoNet is likely to be using for the foreseeable future, so it’s something we’ll no doubt return to in a later data blog. You can find our earlier blog posts through the News section on our web page, just select the Data Blog filter before hitting the Search button. We welcome your feedback on this data blog and if there are any GeoNet data topics you’d like us to talk about please let us know! Ngā mihi nui.
Contact: info@geonet.org.nz